Guidewire Navigation based on Reinforcement Learning
This system places a stent in the target lesion of the coronary artery via a controlling manipulator made by Asan Medical Center. It is the world’s first autonomous PCI robot system. My team developed reinforcement learning-based control software. This project was awarded first place at Johnson & Johnson QuickFire Challenge.
My Role
Development Team Leader
- Design overall system architecture
- Design data flow in system
- Design an experiment process
- Establish experiment environment
- Implement device communication(manipulator, camera) module
- Implement reinforcement learning environment module
Project Detail
Each year, Cardiovascular disease causes a large portion of annual death around the world.
A WHO announcement shows that ischaemic heart disease was the world’s biggest killer in 2016 and one of the most general treatments for ischaemic heart disease is Percutaneous Coronary Intervention.
However, traditional PCI has several drawbacks:
- Large gap of proficiency and difficult transfer of an advanced skill
- Exposure to harmful radiation generated from angiography
- Long time required (about 1 hour)
To overcome these challenges, Medipixel has been collaborating with Asan Medical Center to develop the world’s first autonomous PCI robot system. This system autonomously navigates guide wire to the target lesion, which means it transform an atypical atypical procedure requiring personal skill and experience to typical procedure. The “Standardization of Procedure” process has advantages such as:
- Reducing skill gap between an experienced doctor and a novice doctor
- Reducing exposure time to radiation
- Enabling workers to do other tasks
- Reducing time

Challenges
For a successful PCI procedure, it is necessary to quantify the abstract and complex factors, such as the doctor’s experience and medical knowledge, into proper numerical values in the system. When performing this task, we considered the following issues:
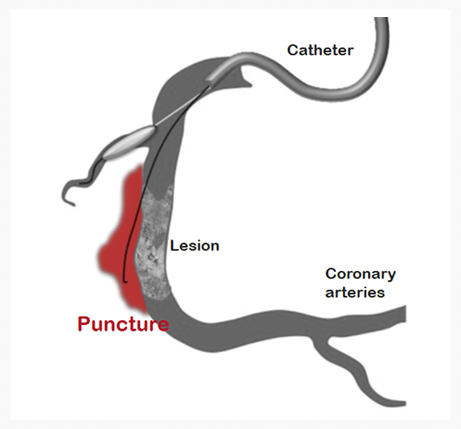
Safety
- There is a possibility that even an unexpected movement of the guidewire can cause a fatal situation in the coronary artery
- Doctors must be able to monitor and intervene in an emergency situation
- Intervention of doctor should be quick
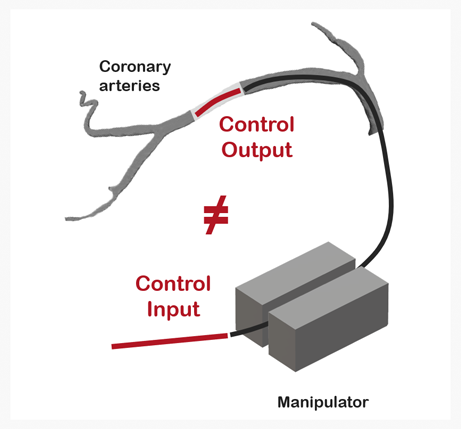
Nonlinearity of manipulation
- Friction and twist of wire can trigger a difference between control input and output
- Manipulation error in a real environment (e.g. wire slip) is another issue in terms of error management
- Control of the flexible body is a traditionally hard problem

Complexity of environment
- Coronary arteries have a complex physical structure including dynamic status changes like blood flow and heartbeat
- It is possible that external factors (e.g. condition of patient) cause abnormal environments
Required Technologies
To undertake the complex project, my team prepared various technologies including medicine, robotics and reinforcement learning.
- To maintain safety, we needed to comprehend the necessary medical knowledge related to PCI
- To achieve robust control, my team surveyed domains such as Robotics and Elastic Rod
- To improve system accuracy, we studied Reinforcement Learning(RL) and Computer Vision Algorithm

Why Reinforcement Learning?
Our environment was so complex that we did not have high confidence in the traditional control method of robotics. Since most of the traditional algorithms are static, they have difficulty handling dynamic environments. Therefore, to accomplish the task, we used an “interaction algorithm” with the dynamic environment.
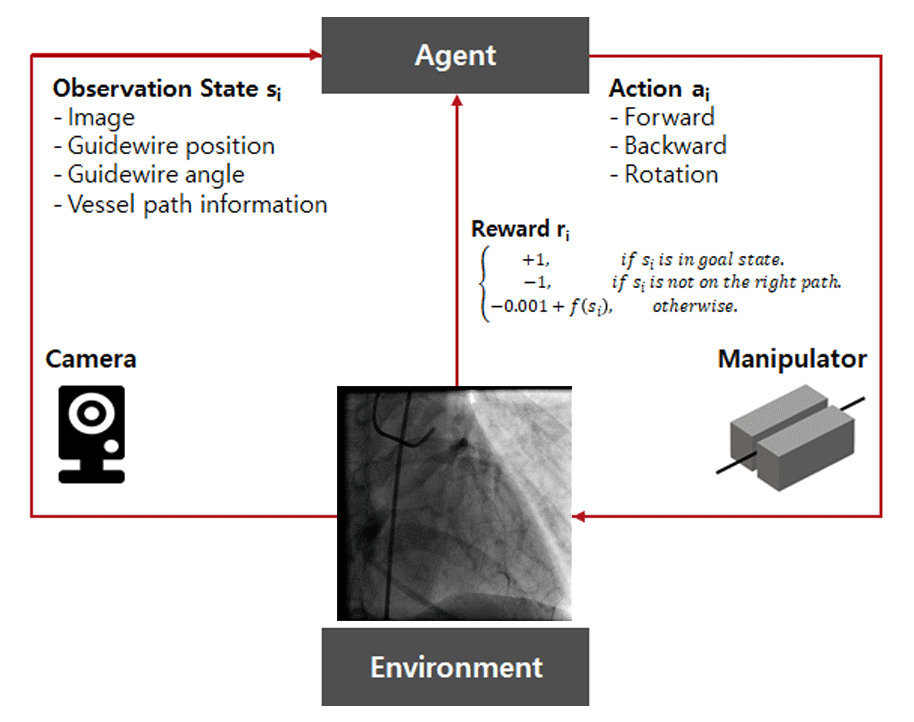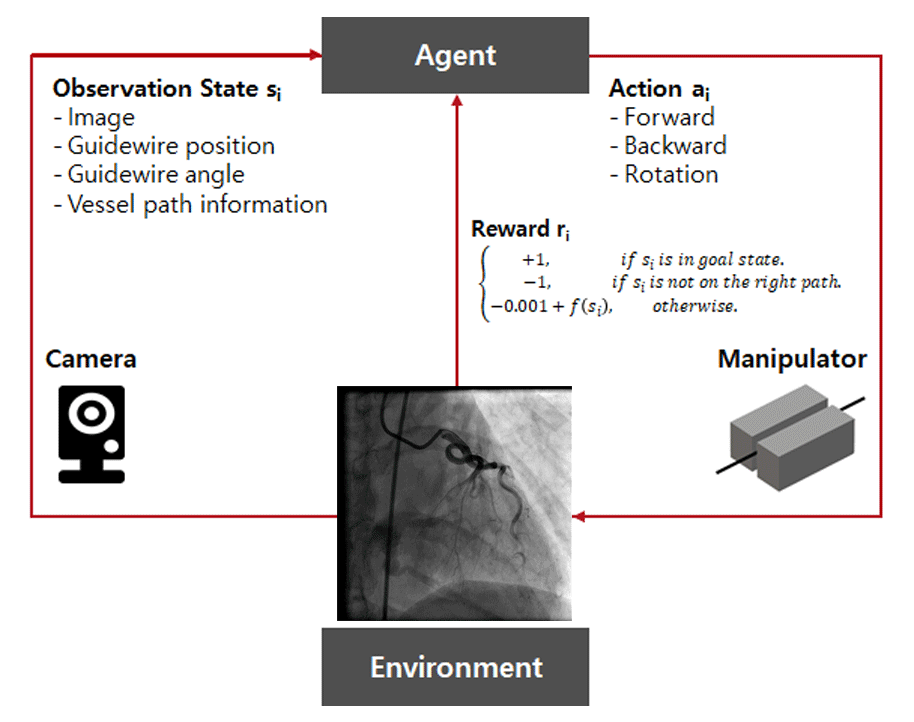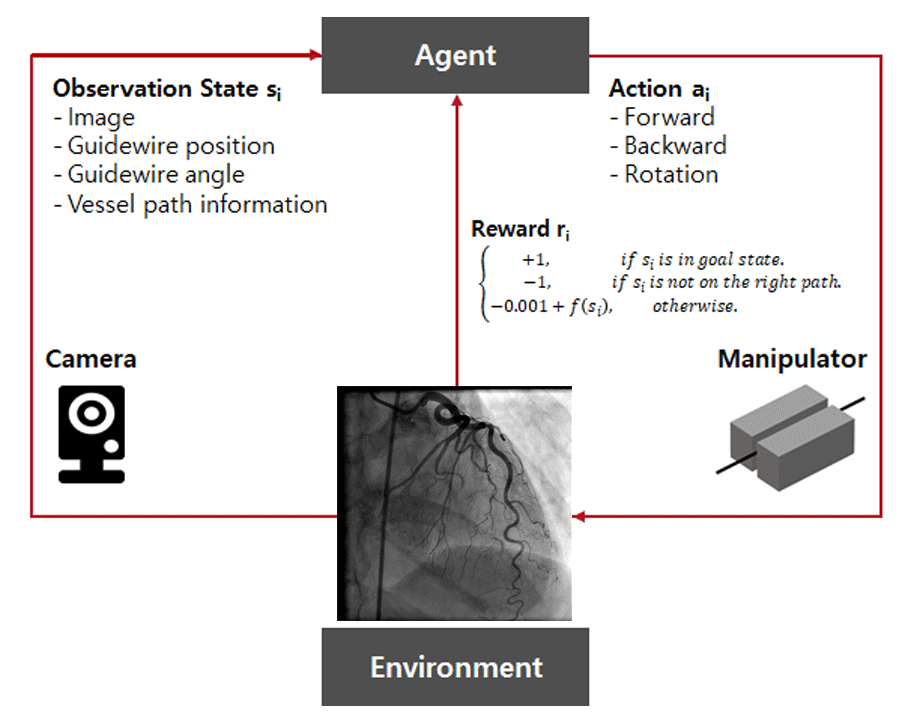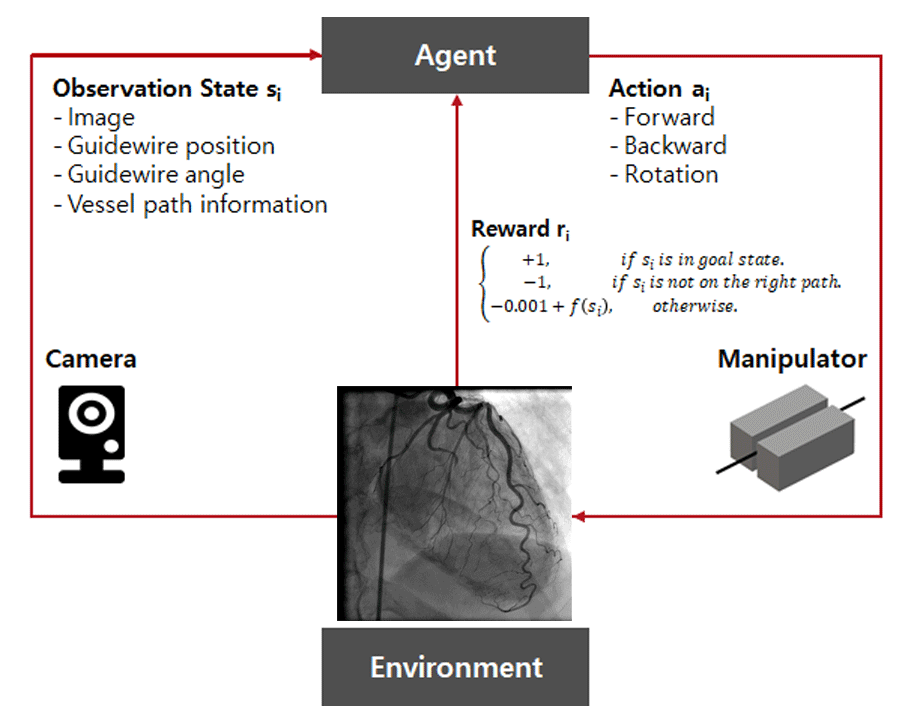
Main Tasks
Planning
To solve such a complex problem, we needed a step-by-step approach. Simplifying the problem, we started at the lowest dimension. First, I set up project stages as follows:
2D → 3D → 3D with vibration → Animal → Clinical environment
Initiation
My role in this project was to decide the direction of development as a development team leader. I divided the complicated main task into several sub-tasks to operationalize the plan. I performed below tasks in each stage:
- Pre-research: To acquire knowledge to build the system
- Set-up: To establish all experiment environments
- Design: To design overall system architecture
- Implementation: To implement the environment module in RL framework and integrate all modules
Pre-research
System Framework
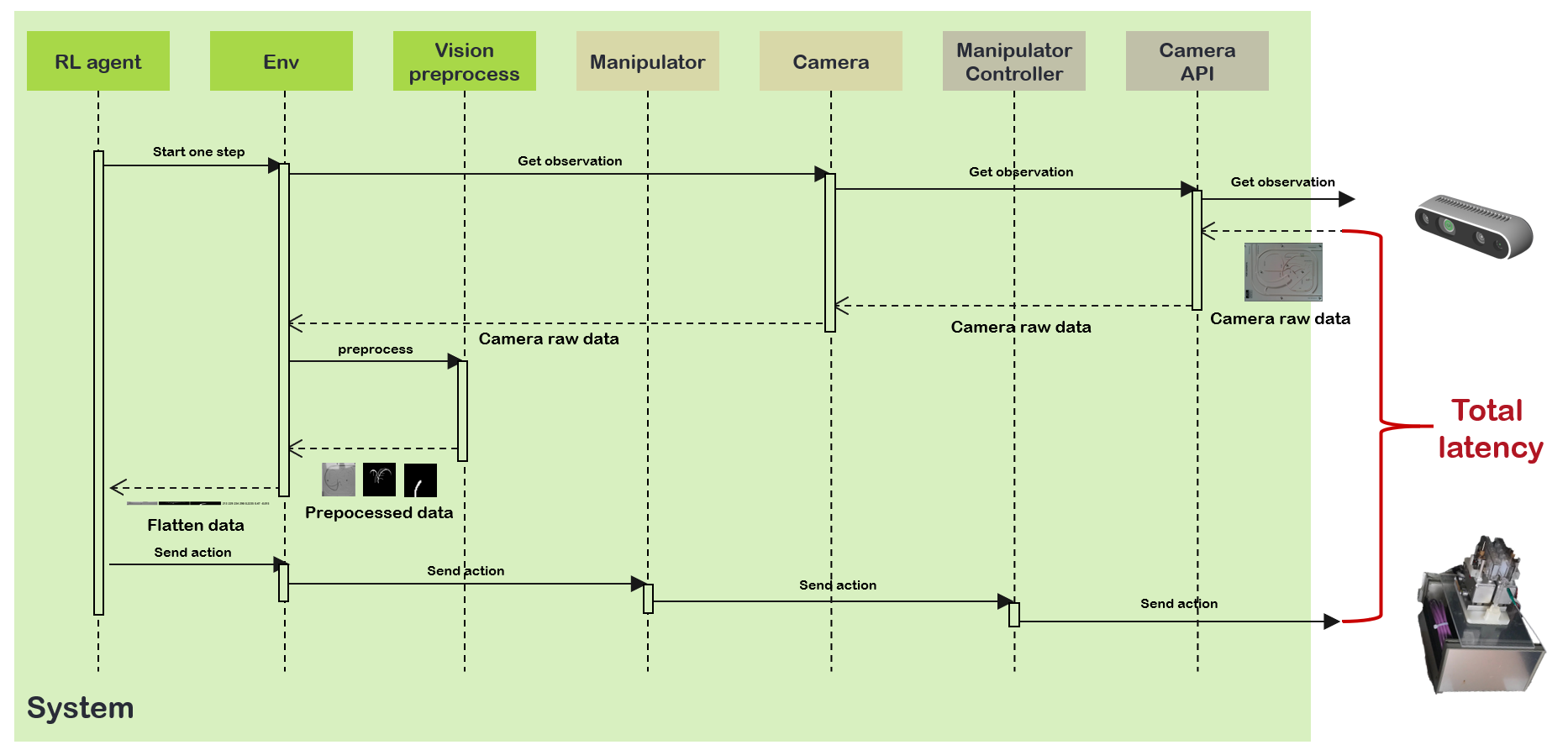
I researched existing systems for RL control in real environments published in various sources (e.g. ICRA, NEMA and Arxiv). Setting up a Reinforcement Learning Task with a Real-World Robot was one of the most helpful experimental result in terms of understanding 1) the relationship between System delays and System performance, 2) training results depending on action space, and 3) the hierarchy of systems in the real world
Medical Knowledge
We conducted interviews with doctors and researchers who have dealt with coronary artery disease. Also, we observed the PCI procedure several times and studied coronary arteries. Through this process, we learned about 1) the procedure of PCI, 2) case studies by patient, 3) usage of equipment, 4) terms/abbreviations and 5) procedure time
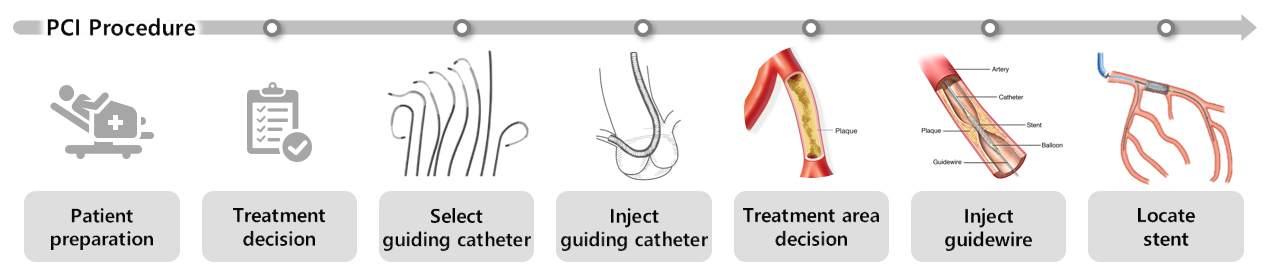
Set-up
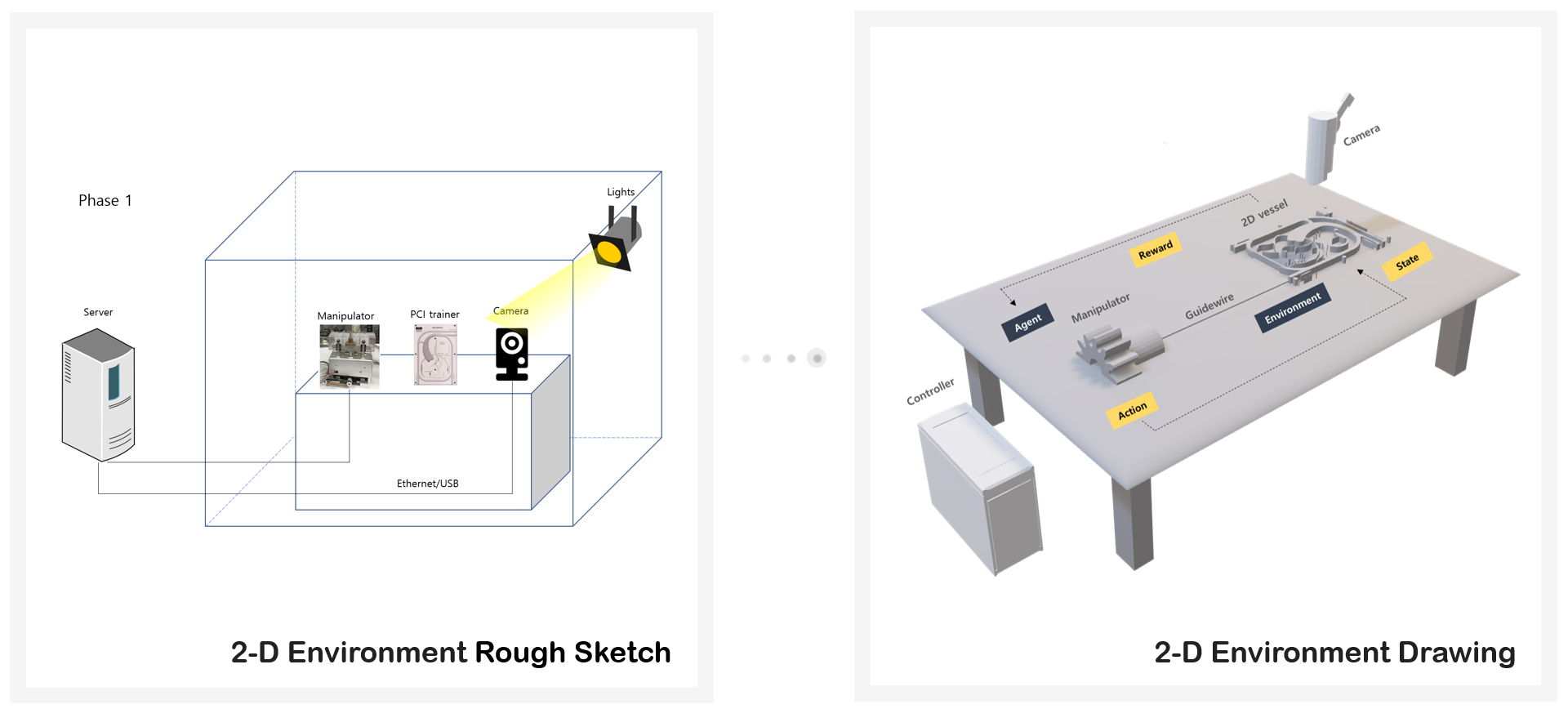
Establishment of Experiment Plan
The first environment was a two dimensional blood vessel model. I selected equipment for the system and drew a rough sketch of the experiment environment. Final expected environment design output is below.
Installation of Darkroom
Vision was the most important input data process for this system. Since vision is sensitive to changes in illumination, I had to exclude natural light from experiment environment and darkroom was the best solution. For this task, I was in charge of purchasing and installing all equipment for the darkroom.

Comparison of Cameras by Latency
Latency is one of the most significant factors for system performance. As a large proportion of latency depended on the camera, I selected a camera model carefully. As seen in the figure below, I conducted latency tests and compared scalability, compatibility, resolution, and latency of the various camera models.

Design Principles
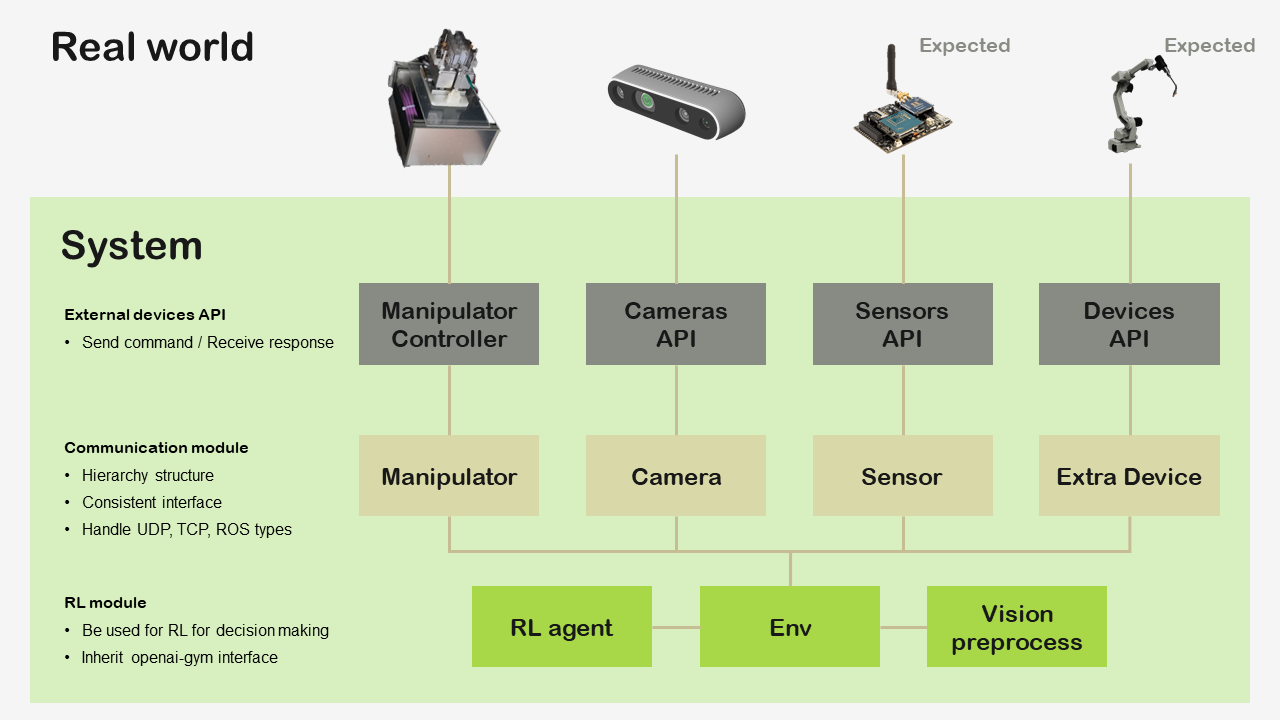
Modularity
Since this system is capable of having diverse environmental conditions like manipulator and external sensor devices, I looked for a way to minimize the number of additional tasks when subsystems or peripherals were changed. I suggested a form on separating the system into submodules by role and made a hierarchy among the submodules.
Scalability
As mentioned above, we planned an environment transition step-by-step. Thus, I had to enable smooth conversion among heterogeneous environments such as 2D, 3D, animal, and clinic. Also, as we needed repetitive experiments for improving system performance like reward shaping, various settings for experiments had to be managed conveniently. I achieved this via an abstract and inheritance structure.
Compatibility
The RL algorithm is necessary to be verified based on a unit test. We used the Atari gym environment for testing. I also considered standard communication protocol connecting with heterogeneous external devices. For this reason, I designed the system using de facto standard systems such as openai-gym and ROS.
Implementation Issues
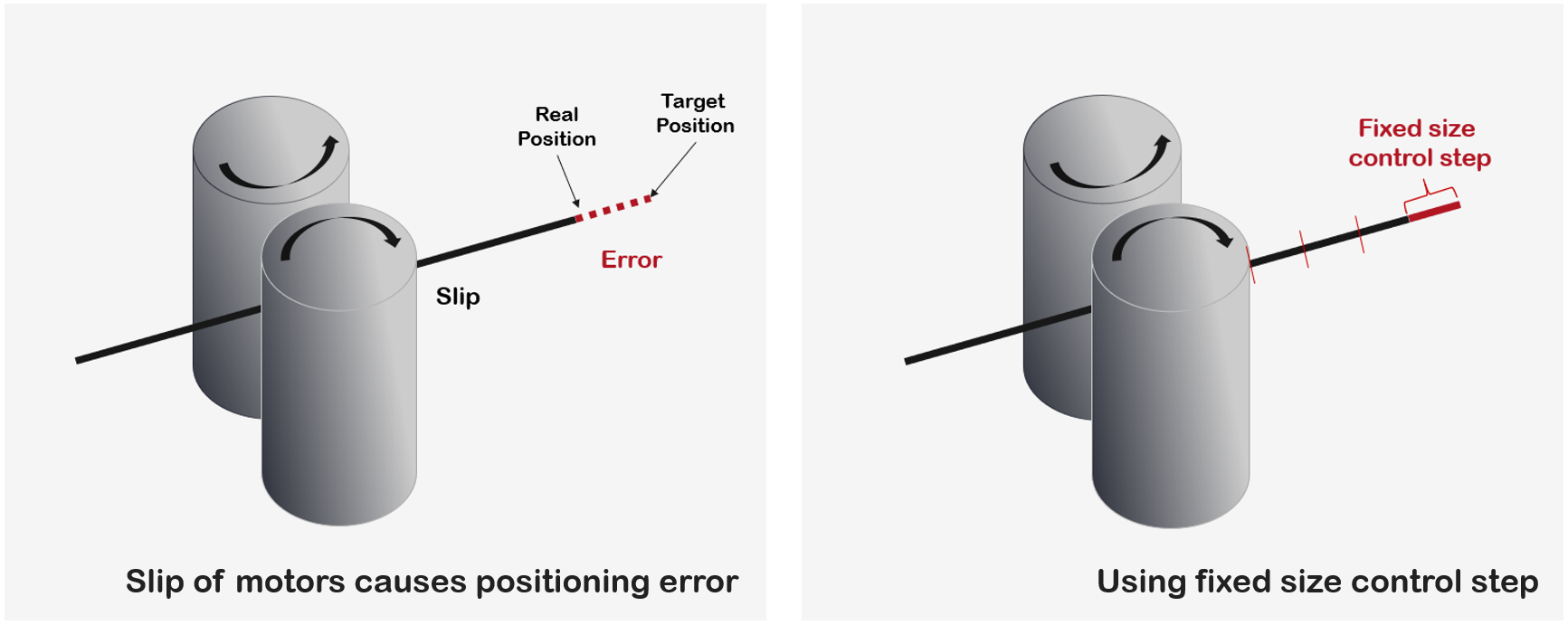
Handling Nonlinearity
There were physical errors during manipulation caused by motor rotation as many general control systems under physical world have. In the coronary artery environment, this kind of error had a worse effect because it requires handling an exquisite unit of space and time. I approached this problem in a heuristic way and tried to define error tolerance thresholds because there is no perfect solution for this issue. Through a trial and error process, my team found that using a very small fixed step command (about 0.05mm) guaranteed that guidewire would be less affected by this problem and able to reach the correct position.
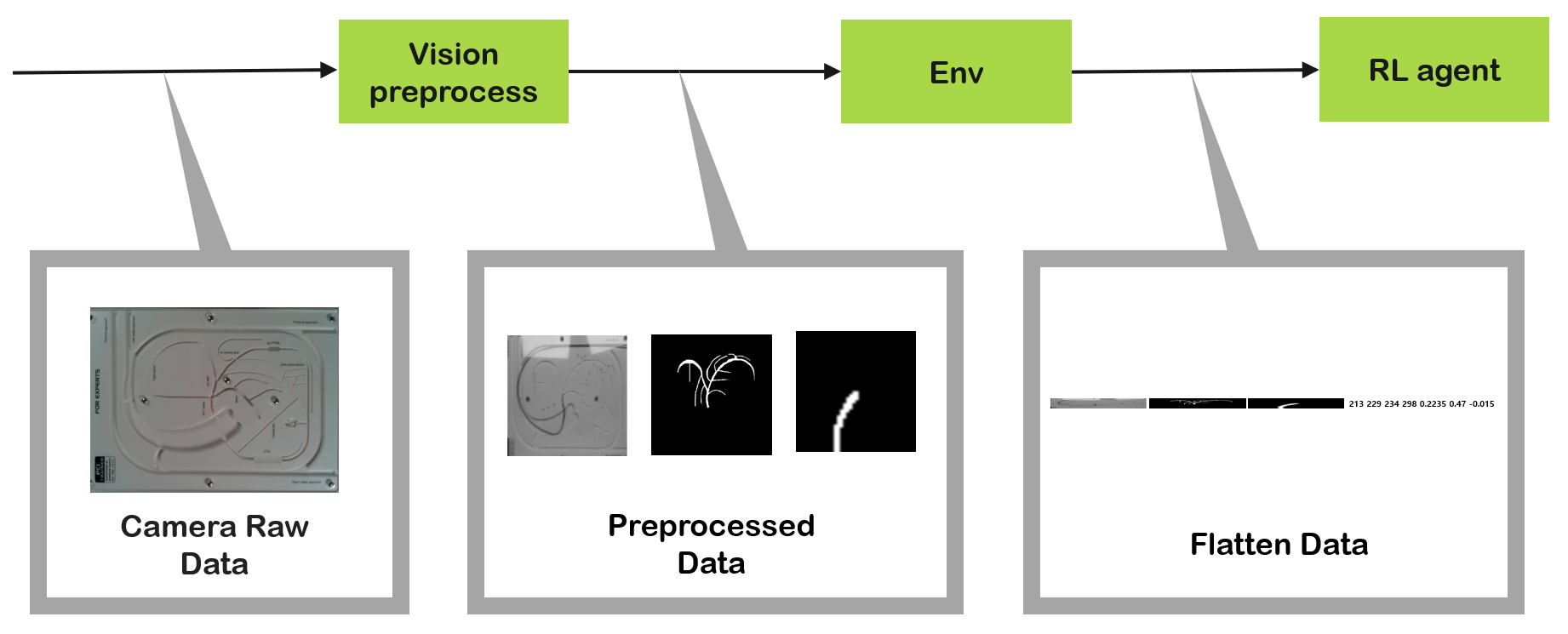
Elaborate Data Flow of Inter-module Communication
To set the proper shape and size of data, there were several trial and error attempts. As the shape of data required in each module was different, I pondered the computational cost of reshaping the data while one module was transferring data to next module. Also, because RL agent utilized experience replay, limitation of memory size for replay buffer was a big issue. Thus, the size of state in RL had to be defined properly.
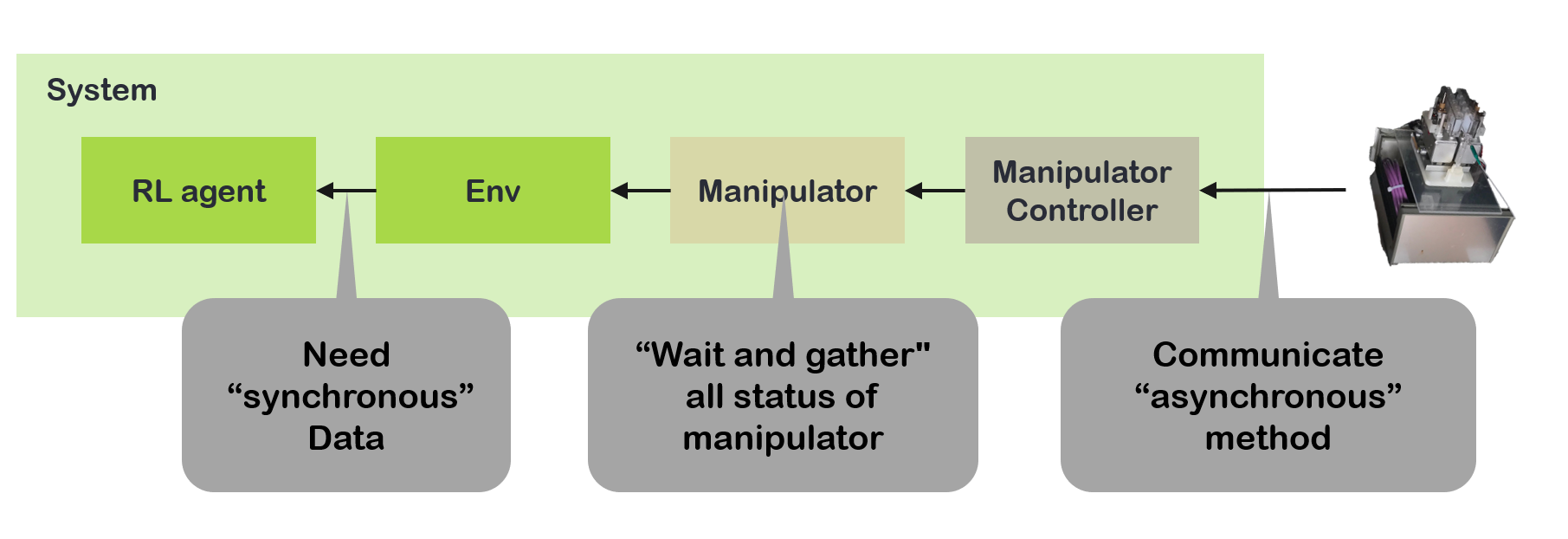
Synchronization Between RL agent and Manipulator
RL agent needs to obtain the necessary data at once for decision making in each time step. As a manipulator operates in asynchronous method, I had to choose the module waiting to collect data from the manipulator for synchronization. I implemented a communication module and put this module in charge of that task.
Reduction of System Latency
Reactivity of the system is one of the most critical factors in overall system performance since agile situational awareness and countermeasures are essential in PCI procedures. Thus, it was imperative to minimize latency on each module because the summation of delayed time took a huge proportion of reactivity. Especially, total latency largely depends on a acquisition time of the camera image and vision preprocessing time.
Strict Exception Handling
It was essential to handle and recover errors that cause harmful results because this system was trained in a real environment. I handled many abnormal situations like a twisted guidewire and path deviation from excessive manipulation. Communication manipulator exception was another serious situation because it could lead to the system procedure being halted.
Experiment
RL Algorithms
My team implemented and ran numerous experiments with RL algorithms to improve system performance.
- Value based algorithms (Rainbow dqn, C51, IQN)
- Demonstration algorithms (Deep Q-learning from Demonstrations)
- Reward Shaping
- Data fusion Execution Timing (Early fusion, Late fusion)
- Additional (Hindsight Experience Replay)
Setup
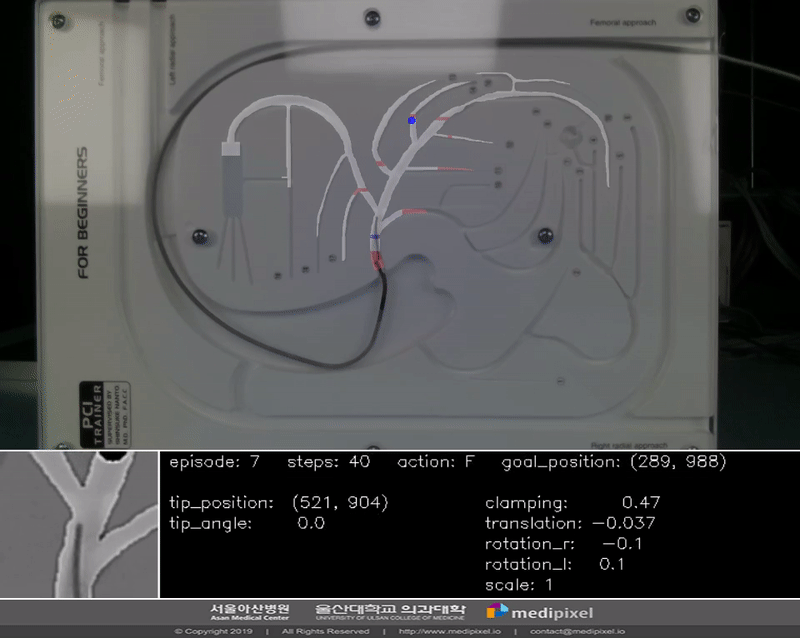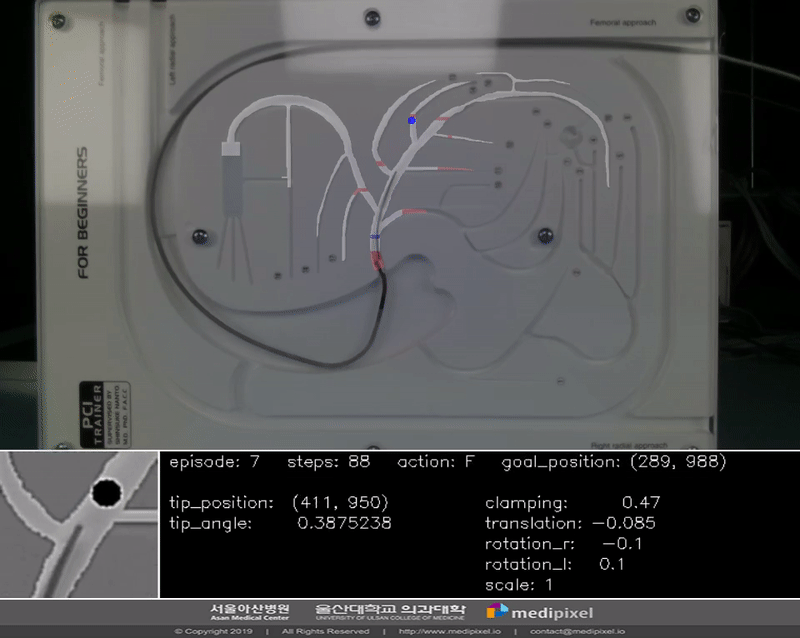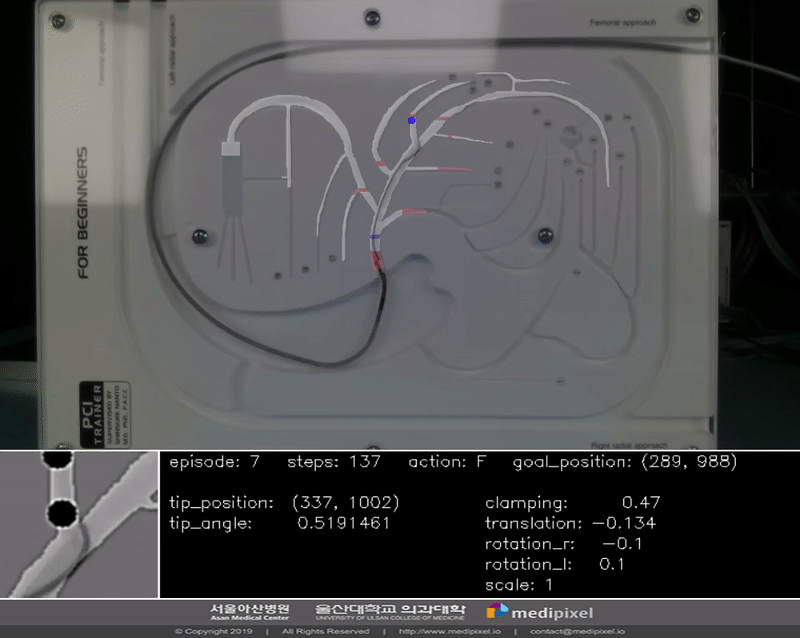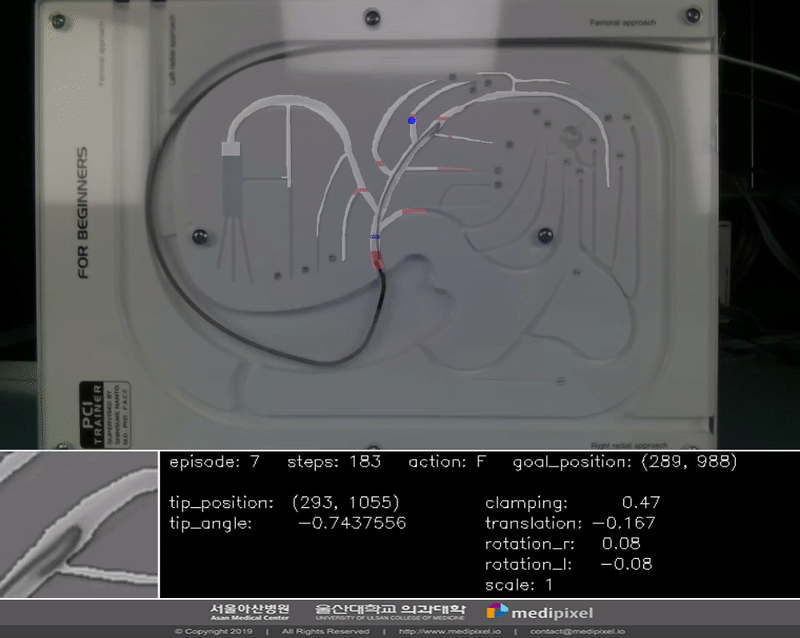
In the guidewire navigation problem, selection of the correct vessel branch is a main issue. Thus, we focused on verifying it and designing the experiment process. The settiing is below:
- Max step is 700
- Rewards are imposed by operating time and path correctness
- Success of episode is to reach the target point within the max step
- Goal positions are as below

Conclusion
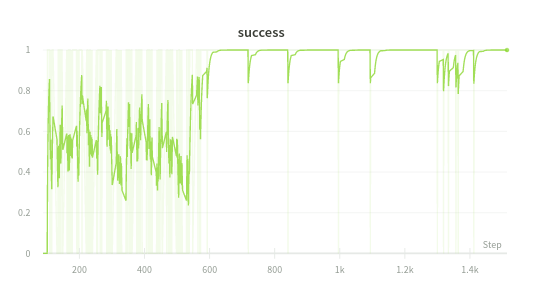
The guidewire successfully achieved our basic goals in the 2D blood vessel. Our navigation system successfully reached the goal position about 95% of the time. Currently, my team and researchers in AMC are writing a research paper targeting TCT, a top tier medical conference.
Success rate
The more training that is carried out, the nearer our success rate moves to 1.0.
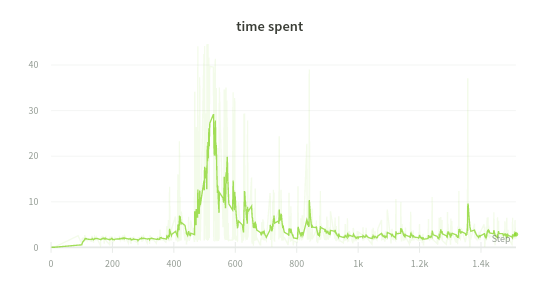
Time spent
In early stage training, the wire moved forward regardless of success. Thus, episode time spent on early stage was short. However, after evolving period (400~600 episode step), the system had a high success rate and takes short time similar to time spent on the early stage.
Further
Possibility to Transfer Other Domain
Because the skill-set includes controlling flexible medium and setting RL environment for control systems, we can utilize it in other fields. We are meeting with people from other fields to find applications of our system to their fields.
| Search system | Pipeline integrity inspection | Catheter procedure automation |
|---|---|---|
 Search system used to locate people in a collapsed building by manipulating wire camera Search system used to locate people in a collapsed building by manipulating wire camera |
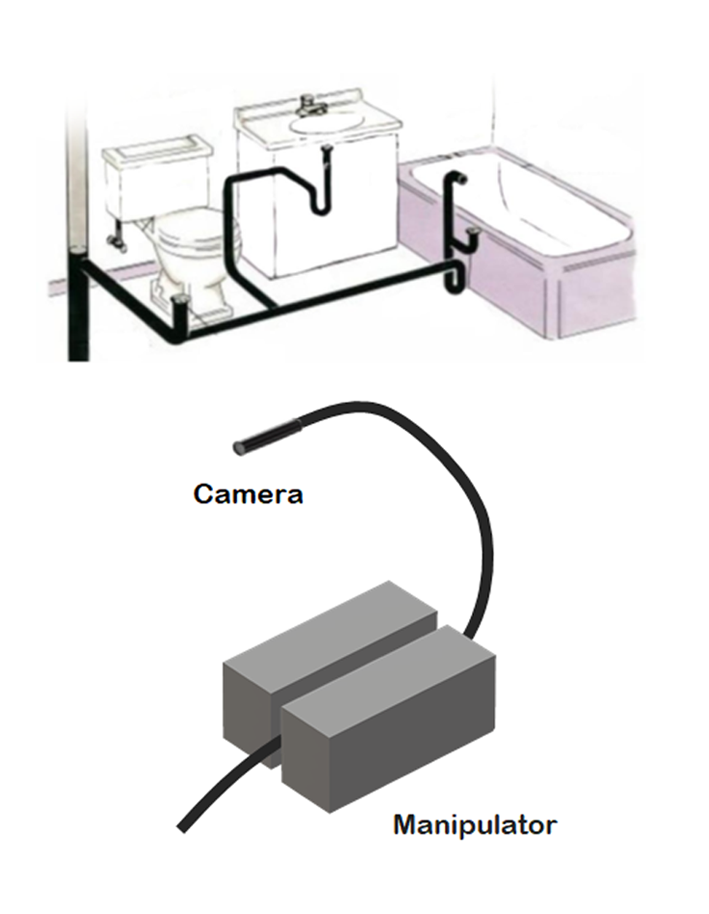 Pipeline integrity inspection in a construction site Pipeline integrity inspection in a construction site |
 Automation of other procedure through wire and catheter Automation of other procedure through wire and catheter |
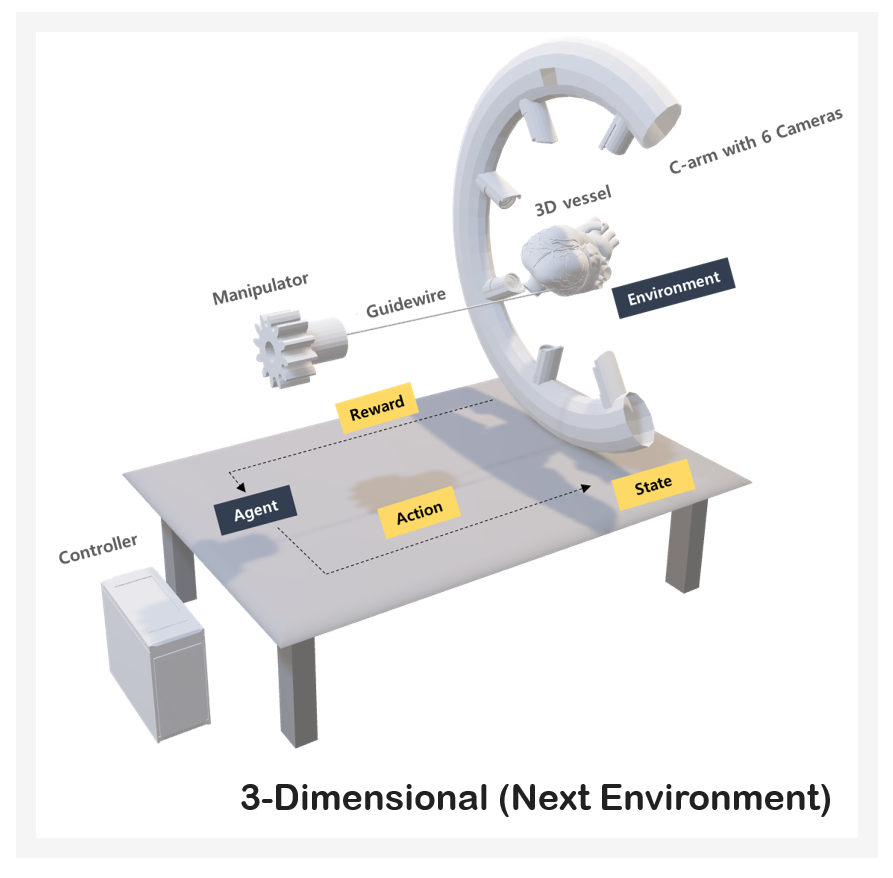
Next Plan
We expect to advance to a new experiment project in a 3D environment in the second half of 2019.
Patent
[1] METHOD AND APPARATUS FOR TRAINING MACHINE LEARNING MODELS TO DETERMINE ACTION OF MEDICAL TOOL INSERTION DEVICE 10-2021-0101640