NeurIPS 2018 - AI for Prosthetics Challenge
My team participated in NeurIPS 2018 - AI for Prosthetics Challenge and took 17th place out of 401 teams. We were able to get valuable practical experiences with reinforcement learning and biomechanics domains.
My Role
System main engineer
- Implement distributed Reinforcement Learning system(RAY) on Cloud system(Azure)
- Implement RL-agent in RAY
Project Detail
AI for Prosthetics Challenge was a official competition in NeurIPS 2018 Competition Track. It used Opensim as a environment. The topic of this competition was to control neuromusculoskeletal model of person with prosthetics in the right leg for moving forward at the given velocity.
We tried many approaches to save time and overcome shortage of resources. First, we researched previous competition and gathered useful information from them. Second, since my team was just two members, we divided the work up between each member cleary. The areas that my team focused on were RL method study, Opensim simulator study and imitation learning study.
Achievements
Since it was the first massive and practical RL project that my team undertook, we had numerous failures. But, in such attempts it was possible to obtain a skill-set to handle practical RL problem.
- Handle complex environment(hundreds state values, 20 action values)
- Handle sparse reward problem in RL
- Build distributed Reinforcement Learning system(RAY) on Cloud system(Azure)
- Utilize imitation learning method
Environment Analysis
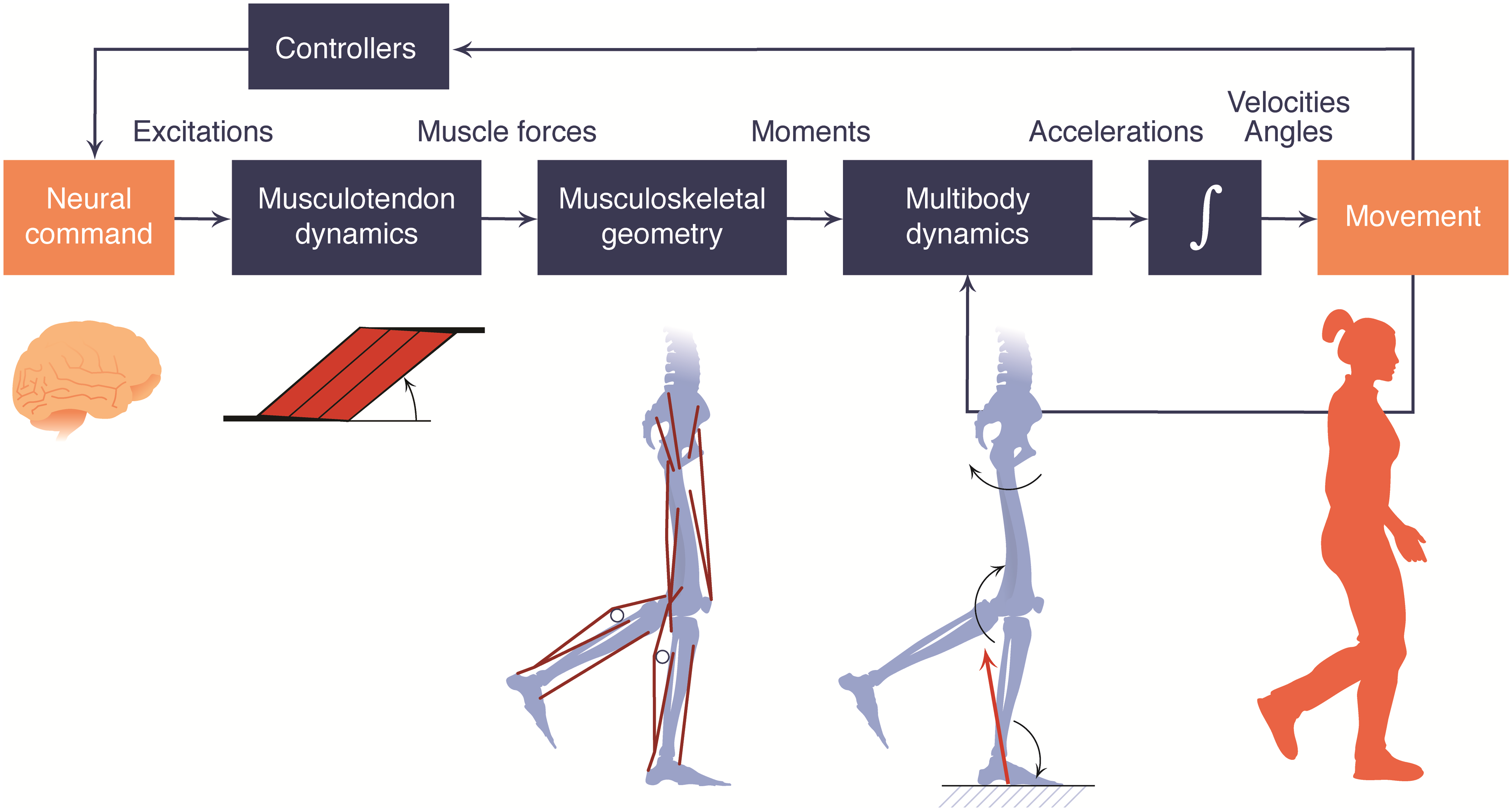
To begin with this competition, I had to analyse unfamiliar environment. As opensim simulation and walking/running gait sequence were far from main task that I had handled before, I put efforts to understand it.
Opensim Environment
First, I started to verify RL environment space. In action space, it was a complex space controlling each muscle one by one compared to other general control methods utilizing joints velocity and angle. Also observation space was relatively complicated, because it had hundreds of data spectated from musculoskeletal.
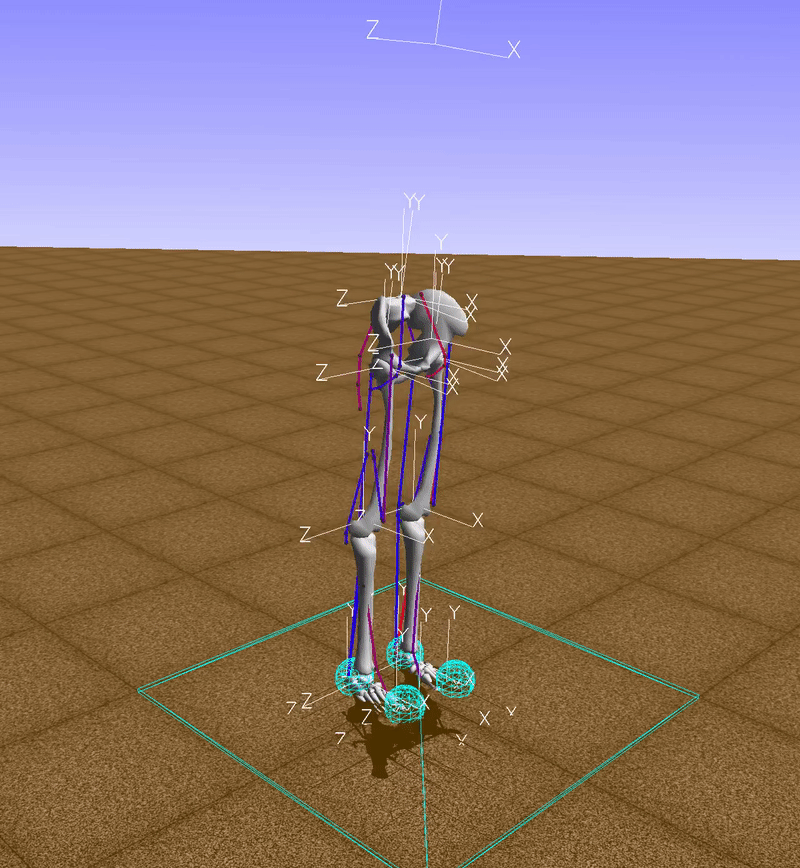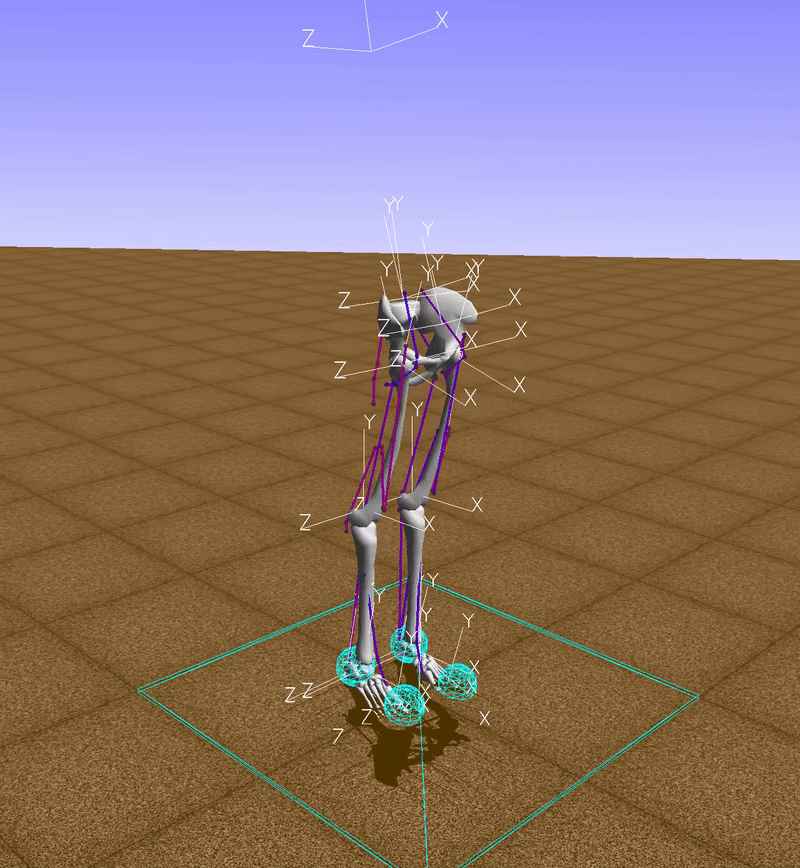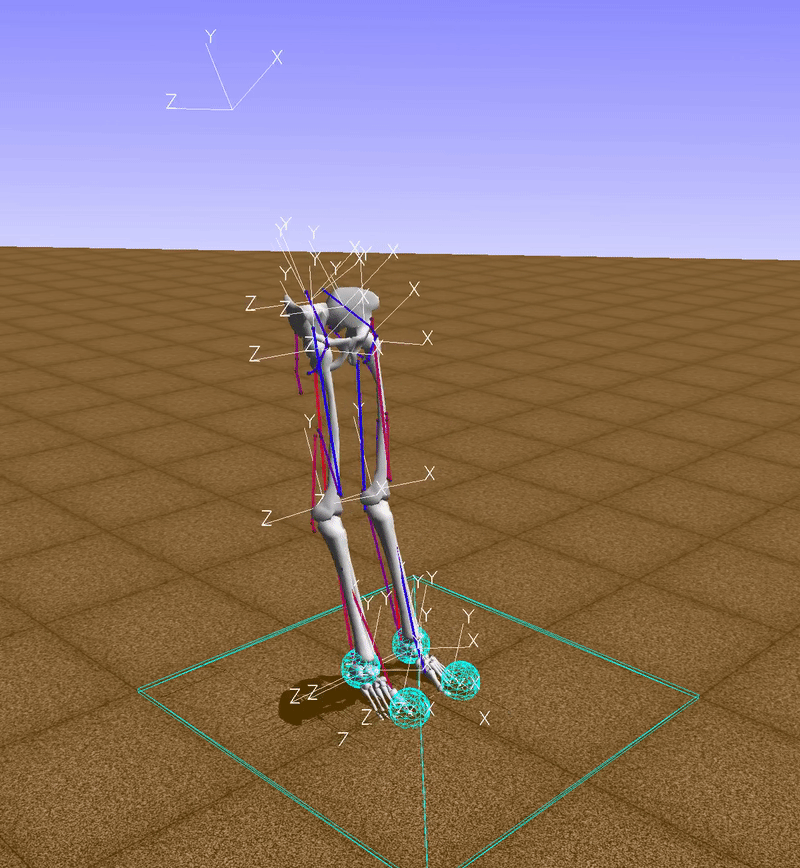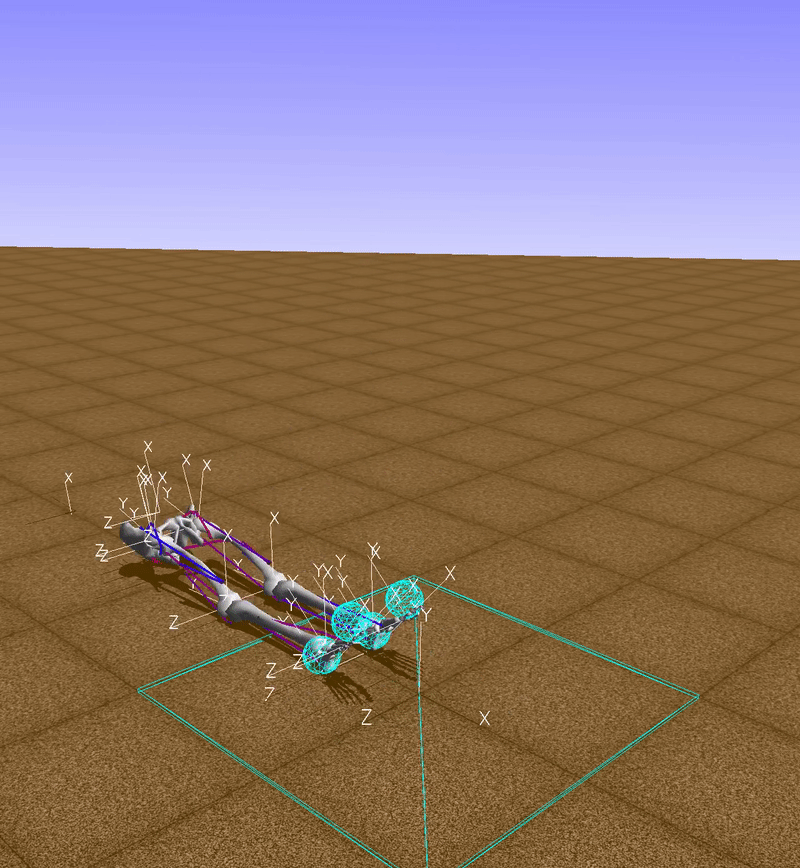
Opensim Tools
To achieve high score, I had to use experimental datasets for walking/running gait sequence in Opensim community. I tried to figure out the pattern of joint movements in gait cycle at the provided dataset. There were several Opensim applications to solve biomechanical problems through forward and Inverse problem.
Furthermore, it was necessary to analyze tools in code level, since built-in application had a limitation and I needed to modify experiment dataset in various ways. After comprehension, I made it possible to customize tools based on project needs.
Utilization of Distributed RL
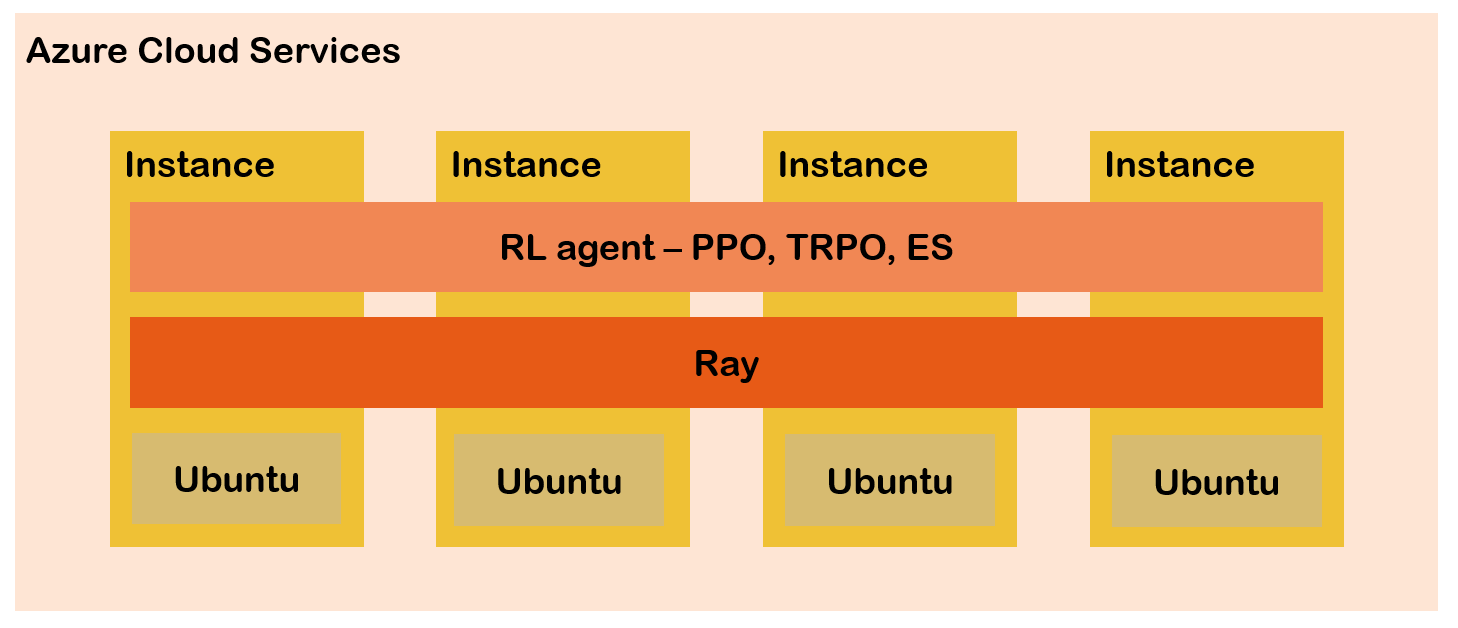
It was one of the most critical problems that interaction with simulator environment needed huge time while training. To improve training performance, my team used distributed Reinforcement Learning system. It was implemented via RAY on Azure cloud server. We operated four cloud servers, and each server instance had 72 high-speed cores. And all of server was clustered via Ray. In result, It was possible to achieve much faster convergence of RL training results.
Imitation Learning
Sparse reward was a big trouble. In this competition, There was no clue for reward of RL agent except for the running speed. I tried to solve this problem with reward shaping and imitation learning method.
Demonstration
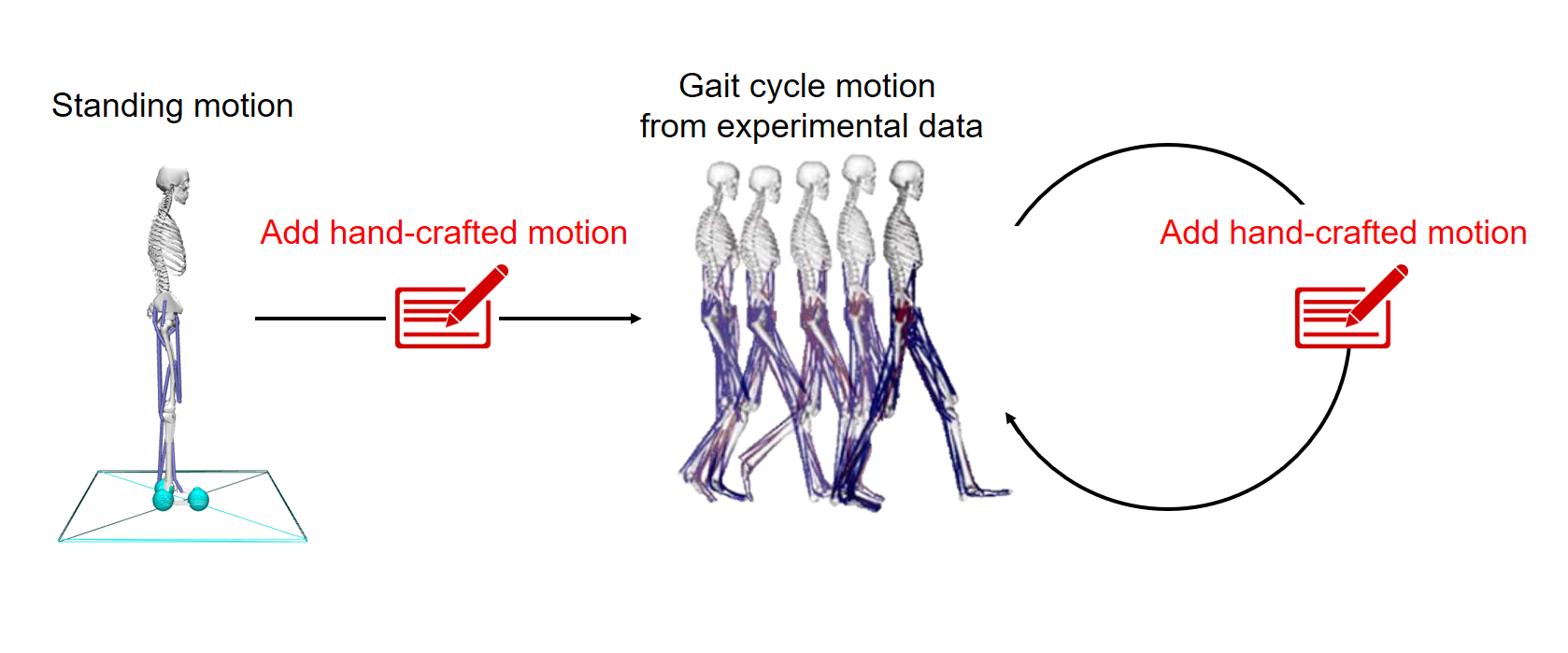
First of all, I created running demonstration from provided dataset because RL agent needed to refer to expert’s trajectories. Having limited period of gait cycle in Experiment dataset, I needed to insert additional kinematic motion data. So, I analysed pattern of gait from other referenced experiments(eg. Muscle contributions to support and progression over a range) and made omitted data.
 |
 |
Behavioral Cloning from Observation
It failed to obtain actions from Opensim application with provided kinematic data. I needed to use a new approach that utilized only kinematic data for training. Behavioral Cloning from Observation(BCO) was one of the best options because Ray had BC agent and it was possible to implement BCO by exploiting built-in BC agent. BCO was a model-based RL method that used model to infer actions from kinematics. Therefore, I implemented BCO agent in Ray.
Deepmimic
Unfortunately, BCO method did not take notable score. Complexity of Opensim environment was too high to obtain meaningful state transition data from not-well-trained agent interactions. So I used state of the art method of imitation learning called Deepmimic. I implemented reward function of Deepmimic in Opensim environment.

Experiment
As deepmimic had a huge parameter set, I had to have many parameter-tuning tasks to improve score until project deadline. Examples of early phase training by various parameters are like below.
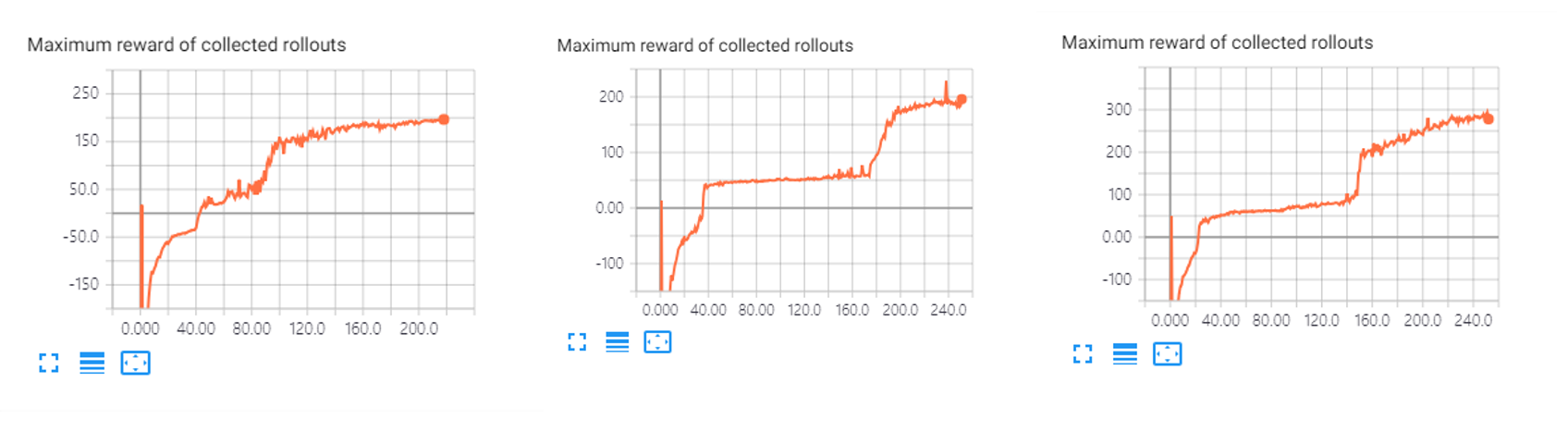
Result
Unlike my expectation, even we used Deepmimic method, agent could not imitate movement of demonstrations perfectly. But Deepmimic was so helpful that agent achieved higher score than heuristic reward shaping method. The final results were like below
 |
 |